
自然语言处理(Natural Language Processing, NLP)是人工智能领域中极具挑战性且充满机遇的研究方向。随着大数据、深度学习等技术的发展,NLP在语音识别、机器翻译、情感分析等领域取得了显著进展,但仍然面临诸多挑战。本文将从技术现状出发,探讨NLP所面临的挑战,并展望其未来发展的机遇。
一、自然语言处理的技术现状
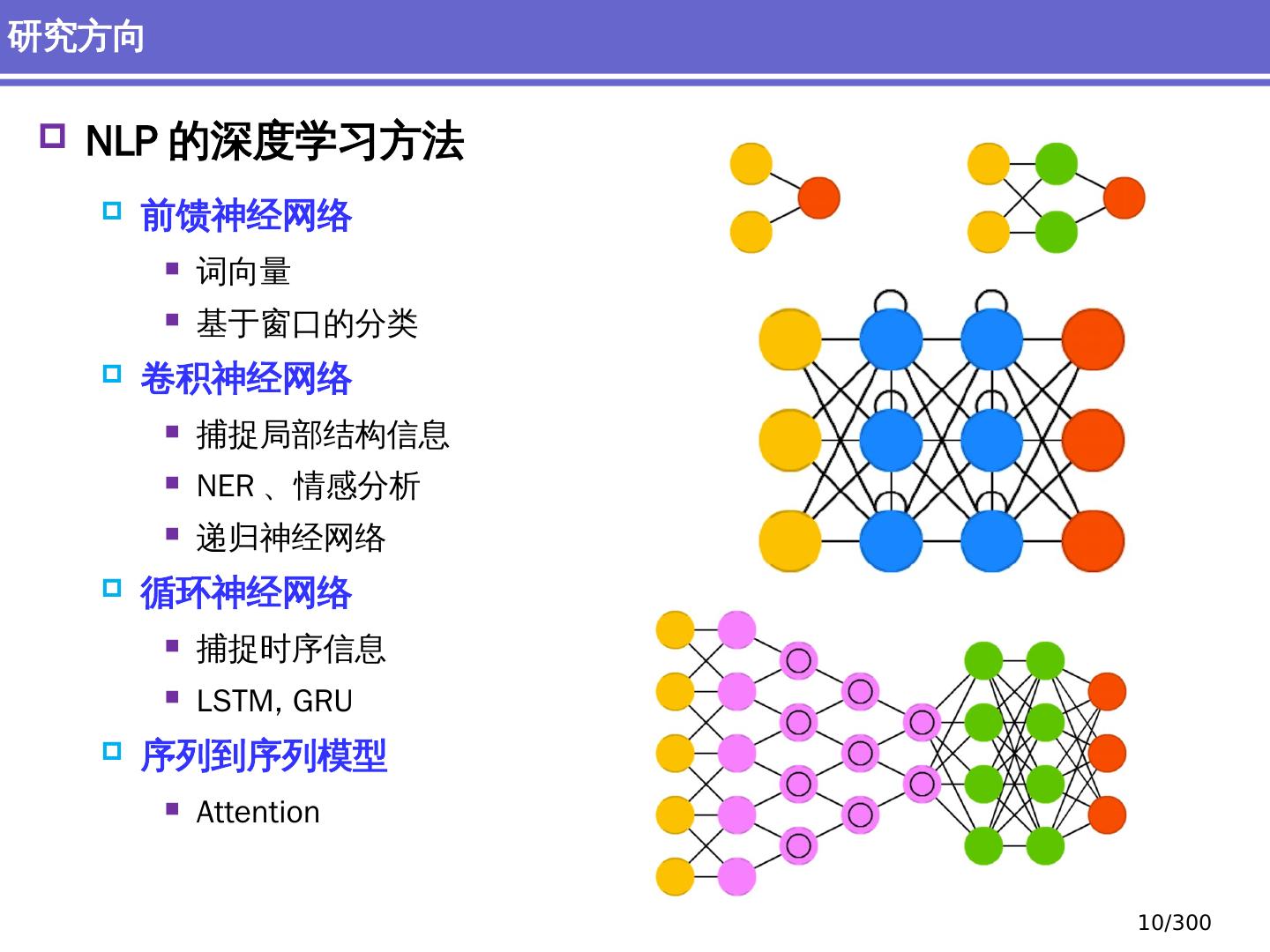
NLP涉及多个学科知识的交叉融合,包括计算机科学、语言学、统计学和心理学等。近年来,深度学习方法在NLP领域的应用日益广泛,如卷积神经网络(CNN)、循环神经网络(RNN)、长短时记忆网络(LSTM)以及Transformer架构等模型在文本分类、命名实体识别、问答系统等方面展现了强大的性能。这些模型能够自动从大规模语料库中学习到语言的内在规律,从而实现对文本的理解与生成。
例如,在机器翻译方面,基于Transformer架构的模型如谷歌的“神经机器翻译”系统(Google Neural Machine Translation)已经能够实现高质量的多语言互译,其准确率大幅超越传统的统计机器翻译方法。预训练语言模型(Pre-trained Language Models)如BERT、RoBERTa等也为NLP任务提供了强有力的工具,它们能够在未标注的数据集上进行预训练,然后针对特定任务进行微调,大大提高了模型的效果。
在文本生成方面,生成对抗网络(GANs)和变分自编码器(VAEs)等生成模型也被引入到NLP中,用于生成自然语言文本。这些模型通过与判别模型协同工作,可以生成符合语法和语义的句子,为创意写作、广告文案撰写等领域带来了新的可能性。
二、自然语言处理面临的挑战
尽管NLP取得了显著进展,但在实际应用中仍然存在许多亟待解决的问题。
(一)多语言与跨文化理解
世界上存在着多种语言和方言,每种语言都有独特的语法结构、词汇表达方式和文化背景。对于多语言环境下的自然语言处理来说,如何有效地处理不同语言之间的差异是一个巨大的挑战。例如,在机器翻译中,源语言和目标语言之间可能存在复杂的映射关系,使得机器难以准确地捕捉到原文的意思。跨文化交流中的语境因素也会对语言的理解产生影响,如果仅依赖于字面意义的翻译,可能会导致误解。因此,开发出能够适应多种语言和文化的通用NLP系统是一项艰巨的任务。
(二)语义理解和推理能力
人类在交流过程中不仅传递信息,还包含着丰富的隐含意义和逻辑关系。当前大多数NLP模型主要关注表面层面的词法和句法结构,对于深层次的语义理解和推理能力还有待提高。例如,在回答问题时,仅仅依靠关键词匹配往往无法获得正确的答案,因为问题可能包含隐含的前提假设或背景知识。为了使机器更好地理解上下文并做出合理的推断,研究人员需要探索更加先进的算法和技术。
(三)数据稀缺性和标注成本
虽然互联网提供了海量的文本数据资源,但由于语言的高度复杂性和多样性,获取高质量的标注数据仍然十分困难。高质量的标注数据对于训练高性能的NLP模型至关重要,但人工标注过程耗时费力且成本高昂。由于不同地区、行业和社会群体之间存在差异,单一来源的数据集可能无法充分反映实际情况,导致模型泛化能力不足。如何有效地利用有限的数据资源来构建有效的NLP模型,是当前研究者们面临的一个重要课题。
(四)伦理与隐私问题
随着NLP技术在各个领域的广泛应用,随之而来的伦理和隐私问题也引起了广泛关注。一方面,自动化决策系统的潜在偏见可能导致不公平的结果;另一方面,用户个人信息的安全保护也面临着严峻考验。为了确保NLP系统的公平性、透明性和安全性,相关法律法规和技术手段都需要不断完善。
三、自然语言处理的机遇
尽管NLP面临诸多挑战,但也蕴含着巨大的发展机遇。
(一)多模态融合
除了文本信息外,图像、音频等多种感官输入形式也为NLP提供了新的视角。通过将视觉、听觉等其他模态的信息与文本相结合,可以构建更加全面的多模态NLP系统。例如,在社交媒体分析中,结合图片和文字内容可以帮助更准确地识别情感状态;在医疗诊断中,结合病历记录和医学影像资料有助于提高疾病预测的准确性。
(二)个性化推荐
借助NLP技术,可以根据用户的兴趣偏好、历史行为等信息为其提供个性化的服务。无论是购物平台的商品推荐,还是在线教育平台的学习路径规划,NLP都能够帮助实现精准匹配,提升用户体验。
(三)人机交互
随着虚拟助手、智能客服等应用场景的普及,人机交互的质量成为了衡量NLP技术水平的重要指标之一。通过不断优化对话管理系统,使机器能够理解用户意图并给出恰当回应,将进一步推动人机交互技术的发展。
自然语言处理作为一门交叉学科,正处于快速发展的阶段。面对当前存在的挑战,我们应积极探索创新解决方案,充分发挥其在各个领域中的潜力,为构建更加智能和谐的社会奠定坚实基础。


发表评论